Deep learning REVIEW--三位大牛的Nature
本文共 3336 字,大约阅读时间需要 11 分钟。
Yann LeCun 扬·勒丘恩 卷积神经网络之父
YoShua Bengio 蒙特利尔教授 吴恩达的师兄弟 Geoffrey Hinton 神经网络之父 三人合作的深度学习文字(好不容易计算机科学能在nature上发表) 深度学习主要通过反向传播来改变程序的内参,卷积神经网络在图像,视频,语音和音频处理上有应用,循环神经网络在文本和语音处理上有好的成效 传统的模式识别和机器学习要用到专业知识继续详细的建模,来搭建一个特征提取器,提取特征,再放入分类器进行分类 深度学习加深了特征提取的深度,转换为更高一些的抽象层面上的表示,更深的特征恒放大区别,以及忽视无关的特征。对于图像进行卷积,第一层特征表现为图像中特定取向和位置的边缘是否存在。第二层通常通过识别特定的边缘布置来检测图案,而不管边缘位置的小的变化。第三层可以将图案组装成对应于熟悉对象的部分的较大组合,并且随后的层将检测对象作为这些部分的组合。深度学习的关键方面是这些特征层不是由人类工程师设计的:他们是通过使用通用学习过程从数据中学习的。这是与之前的机器学习,模式识别最大的区别,这也是深度学习一定程度上被称为黑盒子的原因。 事实证明在高维数据中用深度学习发现复制的关系 非常有用。深度学习在图像,识别,预测潜在的药物活性,分析粒子加速器数据,大脑结构重建,预测突变在非编码DNA的基因表达和疾病上的影响。深度学习在自然语言处理中的主题分类,情感分析 ,问答,语言翻译上有很好的的表现 监督学习 先收集大型数据集,数据其中没个数据都有其标签,标签为其类别,训练过程中, 机器会显示图片以分数向量形式输出每一类的可能性。通过设定一个目标函数,度量输出分数与目标的分数的误差,然后算法根据这个误差调整参数(反向传播),一个系统中肯有以亿记得参数。学习方法一般使用梯度下降的方法来调整参数。 在实践中也有用随机梯度下降的方法:每次调参时不是对所有的样本进行的,而是每次都均匀地抽出一部分样本进行,能极大地加快训练的速度,容易找到较优权重,相对于梯度下降精度较低。 得到特征向量后,用二分类器对特征向量分类进行加权求和,当加权和大于某一阈值是就被归入相应的那一类。 线性分类器只能简单将空间进行分割。在图像,语音上要求输出能对输入的无关变化不敏感(如对象位置光照,音调高低),又要对微小变化敏感(如要区分白狼和萨摩耶)(感觉哈士奇和狼更好一点)。由于两种动物太像,需要一个更好的特征提取器。多选择非线性特征。传统是通过相关领域内的专业知识来设计特征提取器,深度学习可以自己自动学习提取较好的特征。 典型的网络有一个前向传播,获得单元的输出值,再通过激活函数。在大多数网络中多用ReLu,学习速度较快。隐藏层可以看作是以非线性方式扭曲输入,使得类别在最后一层可以线性区分。 1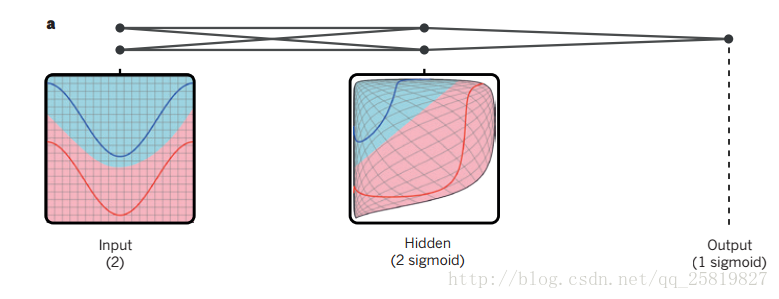 简单的三层进行二分类 2
简单的三层进行二分类 2 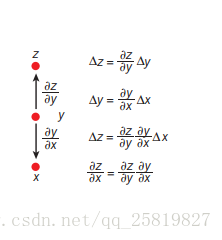 链式传播 3
链式传播 3 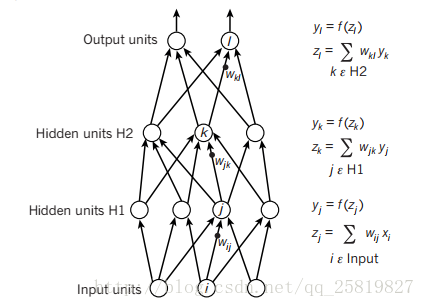
一个人输入层,两个隐藏层,一个输出层 先计算每一个单元的输入加权和,然后用激活函数如ReLU 进行激活,来获得单元的输出
4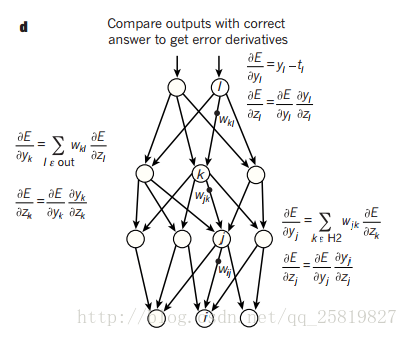 误差的反向传播 先计算出每个输出单元的误差,然后求改误差相对于输入的权重进行求导 在根据梯度下降更改该权值。 1990年后期,神经网络和反向传播被忽视,主要是人们认为多级的特征提取器但没有先验知识是不行的,而且梯度下降会陷入局部最优解。 无监督学习可以创建特定的特征检测层,能对目标进行预训练,使得网络的权重能被初始化为一个较好的值。对于较小的数据集无监督的训练有助于防止过拟合,预训练只需要较小数据 CNN 特点:局部感知(local connections),共享权值(shared weights),池化(pooling)和多层。 CNN主要过程:是卷积算子进行采样,在pooling层降维,再通过激活函数,特征的全连接。
误差的反向传播 先计算出每个输出单元的误差,然后求改误差相对于输入的权重进行求导 在根据梯度下降更改该权值。 1990年后期,神经网络和反向传播被忽视,主要是人们认为多级的特征提取器但没有先验知识是不行的,而且梯度下降会陷入局部最优解。 无监督学习可以创建特定的特征检测层,能对目标进行预训练,使得网络的权重能被初始化为一个较好的值。对于较小的数据集无监督的训练有助于防止过拟合,预训练只需要较小数据 CNN 特点:局部感知(local connections),共享权值(shared weights),池化(pooling)和多层。 CNN主要过程:是卷积算子进行采样,在pooling层降维,再通过激活函数,特征的全连接。 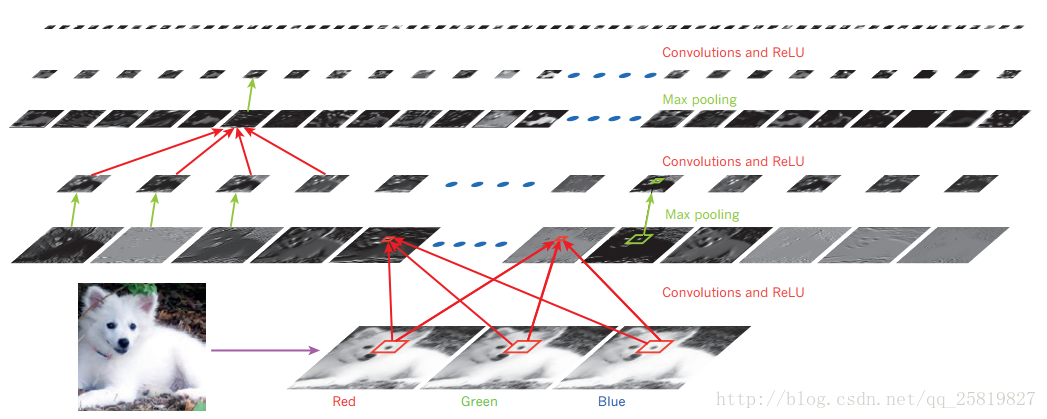 其中pooling层能将相邻的特征和为1个对特征能降低特征的维度,也能获得一定的平移和形变不变性。
其中pooling层能将相邻的特征和为1个对特征能降低特征的维度,也能获得一定的平移和形变不变性。 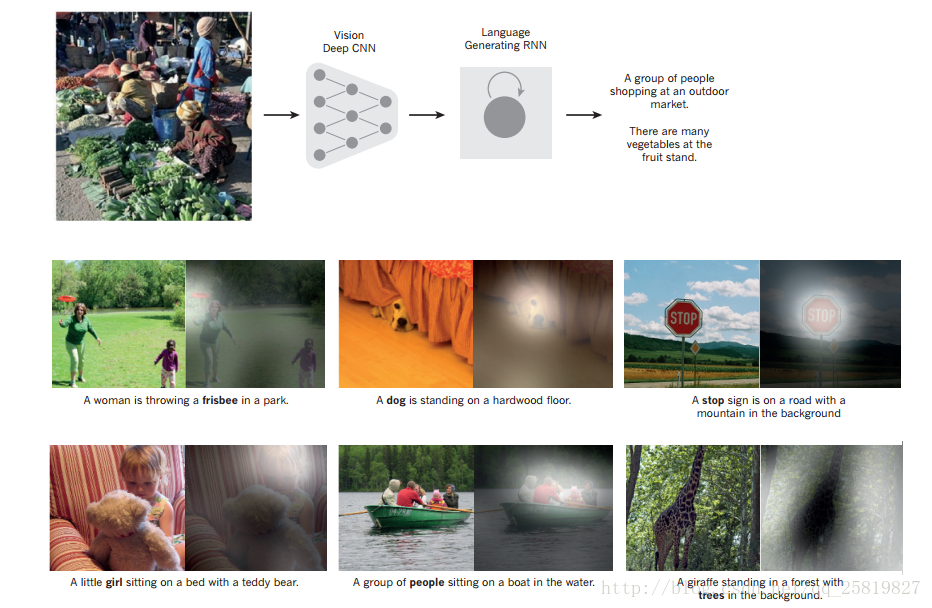 在图像理解中,由递归神经网络(RNN)生成的字幕将来自测试图像的由深度卷积神经网络(CNN)提取的表示作为额外输入,其中RNN被训练成将图像的高级表示“翻译”为字幕。当RNN能够把注意力集中在输入图像中的不同位置(中间和底部;较轻的补丁被更多地关注),因为它产生每个单词(粗体),我们发现它利用这个 实现更好的图像翻译成字幕 深度学习相对于传统的学习的优点: 1:深度学习的分布式表示可以推广到特征值的组合 2:深度学习的层次深度可以带来巨大的潜力(事实证明确实如此,如152层的残差网络) Visualizing the learned word vectors可视化单词向量(有点像word2vector) 在左边是用于建模语言学习的词表示的示意图,非线性投影到2D使用t-SNE算法进行可视化。 右边是一个由英语到法语编码器 - 解码器递归神经网络学习的短语用2D表示。 可以观察到,语义上相似的单词或单词序列被映射到附近的表示。 通过使用反向传播联合学习每个单词的表示和预测目标数量的函数(例如,用于语言模型的序列中的下一个单词)或翻译的单词的整个序列(用于机器翻译)来获得单词的分布式表示)。
在图像理解中,由递归神经网络(RNN)生成的字幕将来自测试图像的由深度卷积神经网络(CNN)提取的表示作为额外输入,其中RNN被训练成将图像的高级表示“翻译”为字幕。当RNN能够把注意力集中在输入图像中的不同位置(中间和底部;较轻的补丁被更多地关注),因为它产生每个单词(粗体),我们发现它利用这个 实现更好的图像翻译成字幕 深度学习相对于传统的学习的优点: 1:深度学习的分布式表示可以推广到特征值的组合 2:深度学习的层次深度可以带来巨大的潜力(事实证明确实如此,如152层的残差网络) Visualizing the learned word vectors可视化单词向量(有点像word2vector) 在左边是用于建模语言学习的词表示的示意图,非线性投影到2D使用t-SNE算法进行可视化。 右边是一个由英语到法语编码器 - 解码器递归神经网络学习的短语用2D表示。 可以观察到,语义上相似的单词或单词序列被映射到附近的表示。 通过使用反向传播联合学习每个单词的表示和预测目标数量的函数(例如,用于语言模型的序列中的下一个单词)或翻译的单词的整个序列(用于机器翻译)来获得单词的分布式表示)。 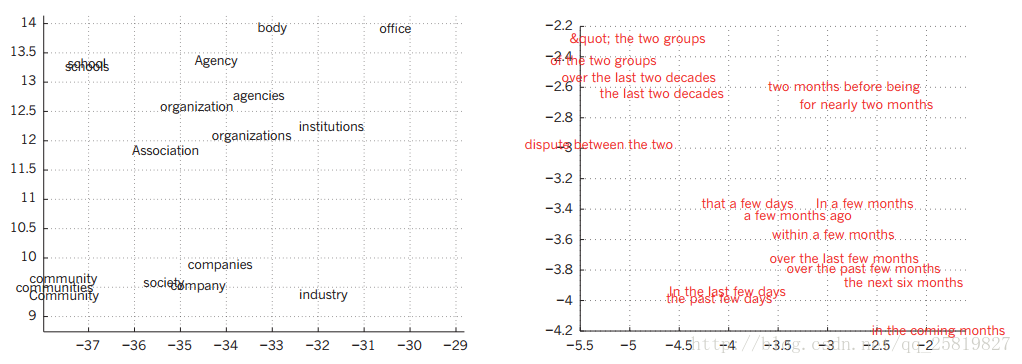 多层神经网络的隐藏层学会以一种方式表示网络的输入,使预测变得容易。多层神经网络能较好的预测单词的顺序 通过将单词转化为向量。网络将输入单词转化为下一个单词是什么出现的概率。 网络学习单词向量包含许多有效的组件,每个组件可以被解释为单词的单独的特征, 这些语义特征在输入中没有明确表示。通过输入和输出符号之间可以结构化分解成多个微观规则。 代表性的问题是逻辑启发和神经网络启发的认知范式之间争论的核心。 在逻辑启发的范例中,符号的一个实例是唯一的属性,它与其他符号实例相同或不相同。 它没有与其使用有关的内部结构; 并用符号来推理,它们必须在明智选择的推理规则中受到变量的约束。 相比之下,神经网络只是使用大活动向量,大权重矩阵和标量非线性来执行快速“直观”推断的类型,这是支持毫不费力的常识推理 Recurrent neural networks递归神经网络 当数据涉及顺序输入如语音和语义时RNN有更好的效果。 RNN一次处理一个输入序列的一个元素,在其隐藏的单元中保存一个“状态向量”,隐含地包含关于该序列的所有过去元素的历史的信息。 RNN在是动态的,在训练的时候梯度每个时间都会增长或缩小所以梯度在某一时间会爆炸或者消失 一种递归神经网络和在时间上的展开的前向计算 人造神经元(例如,在节点s下分组的,在时间t处具有值st的隐藏单元)在之前的时间步骤从其他神经元获得输入(这用黑色方框表示,表示一个时间步长的延迟,在左边) 。这样,一个循环神经网络可以将元素x,t的输入序列映射为输出序列的元素ot,每个ot取决于前面所有的x t’(对于t’≤t)。在每个时间步使用相同的参数(矩阵U,V,W)。许多其他体系结构也是可能的,包括网络可以生成一系列输出(例如单词)的变体,每个输出都被用作下一个时间步的输入。反向传播算法可以直接应用于右侧展开网络的计算图,计算总误差的导数(例如,产生正确输出序列的对数概率)至所有的状态和所有的参数 在图片翻译时 CNN起到编码器作用 将像素转化为向量,RNN起解码器作用将向量转化为文字。 RNN一旦展开(图5),可以看作是所有层共享相同权重的非常深的前馈网络。 虽然他们的主要目的是学习长期的依赖关系,理论和经验证据表明,很难学习长时间存储信息。 然后又有了LSTM(long short-term memory,长短记忆网络),其自然行为是长时间记忆输入。 有一个称为存储单元的特殊单元就像一个累加器或一个门控漏泄神经元:它在下一个时间步有一个权重为1的连接,所以它复制自己的实值状态并累积外部信号, 但是这个自连接是由另一个学习决定何时清除内存内容的单元乘上门控的。 文末大佬们预测: 1:无监督学习会变的重要 2:.注意力模型(局部高分辨率)会在视觉中发挥作用 RNN+CNN可以决定注意力 3:NLP会对其他领域产生影想 4:新的范式来取代对大型矢量进行操作的符号表达式的基于规则的操作
多层神经网络的隐藏层学会以一种方式表示网络的输入,使预测变得容易。多层神经网络能较好的预测单词的顺序 通过将单词转化为向量。网络将输入单词转化为下一个单词是什么出现的概率。 网络学习单词向量包含许多有效的组件,每个组件可以被解释为单词的单独的特征, 这些语义特征在输入中没有明确表示。通过输入和输出符号之间可以结构化分解成多个微观规则。 代表性的问题是逻辑启发和神经网络启发的认知范式之间争论的核心。 在逻辑启发的范例中,符号的一个实例是唯一的属性,它与其他符号实例相同或不相同。 它没有与其使用有关的内部结构; 并用符号来推理,它们必须在明智选择的推理规则中受到变量的约束。 相比之下,神经网络只是使用大活动向量,大权重矩阵和标量非线性来执行快速“直观”推断的类型,这是支持毫不费力的常识推理 Recurrent neural networks递归神经网络 当数据涉及顺序输入如语音和语义时RNN有更好的效果。 RNN一次处理一个输入序列的一个元素,在其隐藏的单元中保存一个“状态向量”,隐含地包含关于该序列的所有过去元素的历史的信息。 RNN在是动态的,在训练的时候梯度每个时间都会增长或缩小所以梯度在某一时间会爆炸或者消失 一种递归神经网络和在时间上的展开的前向计算 人造神经元(例如,在节点s下分组的,在时间t处具有值st的隐藏单元)在之前的时间步骤从其他神经元获得输入(这用黑色方框表示,表示一个时间步长的延迟,在左边) 。这样,一个循环神经网络可以将元素x,t的输入序列映射为输出序列的元素ot,每个ot取决于前面所有的x t’(对于t’≤t)。在每个时间步使用相同的参数(矩阵U,V,W)。许多其他体系结构也是可能的,包括网络可以生成一系列输出(例如单词)的变体,每个输出都被用作下一个时间步的输入。反向传播算法可以直接应用于右侧展开网络的计算图,计算总误差的导数(例如,产生正确输出序列的对数概率)至所有的状态和所有的参数 在图片翻译时 CNN起到编码器作用 将像素转化为向量,RNN起解码器作用将向量转化为文字。 RNN一旦展开(图5),可以看作是所有层共享相同权重的非常深的前馈网络。 虽然他们的主要目的是学习长期的依赖关系,理论和经验证据表明,很难学习长时间存储信息。 然后又有了LSTM(long short-term memory,长短记忆网络),其自然行为是长时间记忆输入。 有一个称为存储单元的特殊单元就像一个累加器或一个门控漏泄神经元:它在下一个时间步有一个权重为1的连接,所以它复制自己的实值状态并累积外部信号, 但是这个自连接是由另一个学习决定何时清除内存内容的单元乘上门控的。 文末大佬们预测: 1:无监督学习会变的重要 2:.注意力模型(局部高分辨率)会在视觉中发挥作用 RNN+CNN可以决定注意力 3:NLP会对其他领域产生影想 4:新的范式来取代对大型矢量进行操作的符号表达式的基于规则的操作
你可能感兴趣的文章
linux创建用户
查看>>
Pig Hive对比(zz)
查看>>
PageValidate 类
查看>>
ubuntu建立快捷方式
查看>>
java的基本数据类型
查看>>
C++ 之引用
查看>>
远程重启WIN服务器
查看>>
tomcat
查看>>
[转]linq to sql 插入值,以及如何取回自增的ID
查看>>
测试笔记1
查看>>
Java学习笔记(5)----使用正则表达式解决Google Code Jam Qualification2009赛题 Alien Language...
查看>>
VSCode 拓展插件推荐
查看>>
PS 使用笔记 - PS 让工作台适应 当前图层
查看>>
系统整理
查看>>
OpenSuSe开启sshd服务
查看>>
运维自动化发展
查看>>
Vue开发插件的简单步骤
查看>>
文件方式实现完整的英文词频统计实例
查看>>
Oracle活动会话历史(ASH)及报告解读
查看>>
Project Euler Problem 7: 10001st prime
查看>>